The companion paper
Bottleneck-Driven Projection of Frontier-Class LLM Inference on Dedicated ASICs · v0.2 (2026-04-22)
What it shows
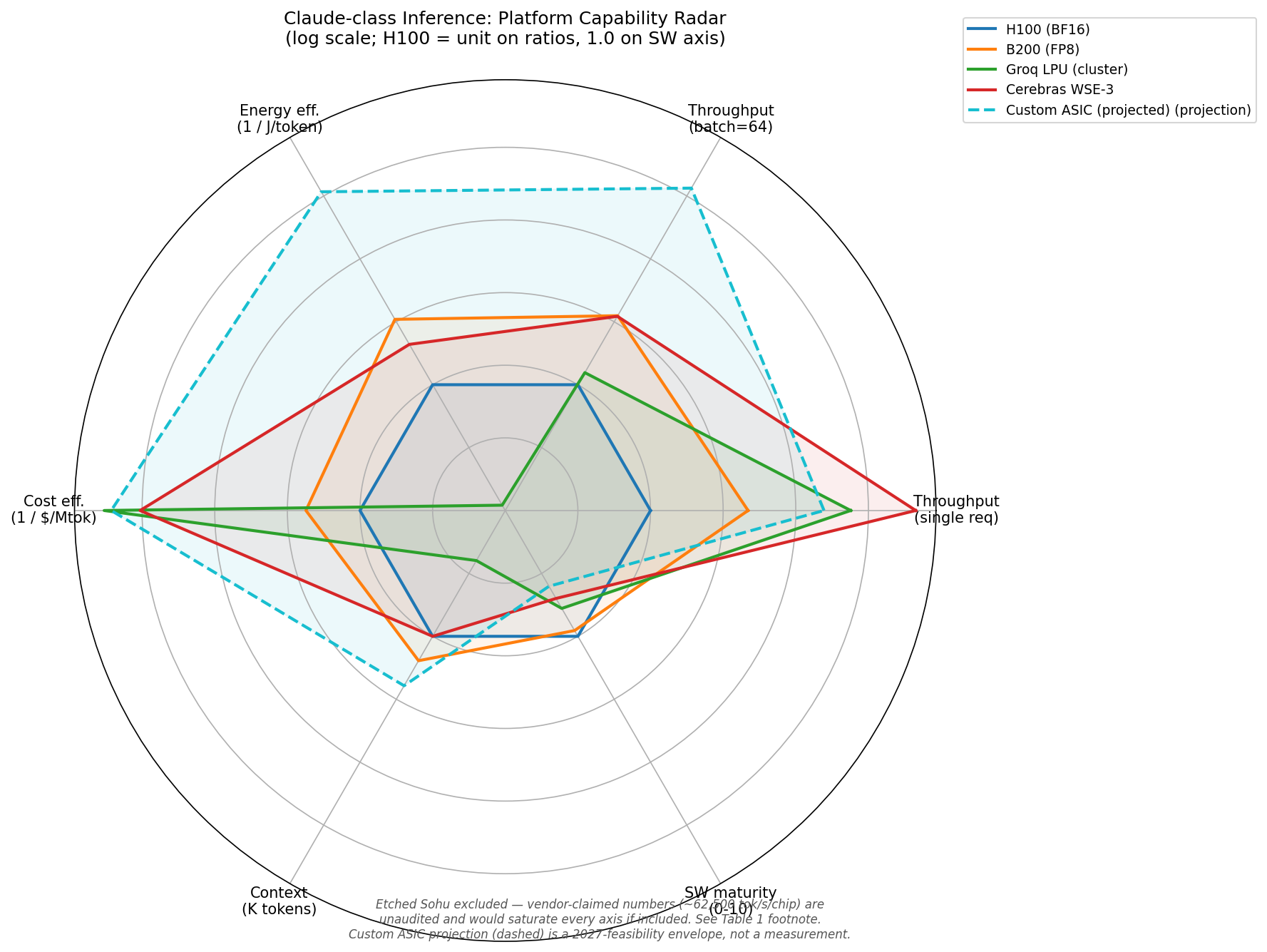
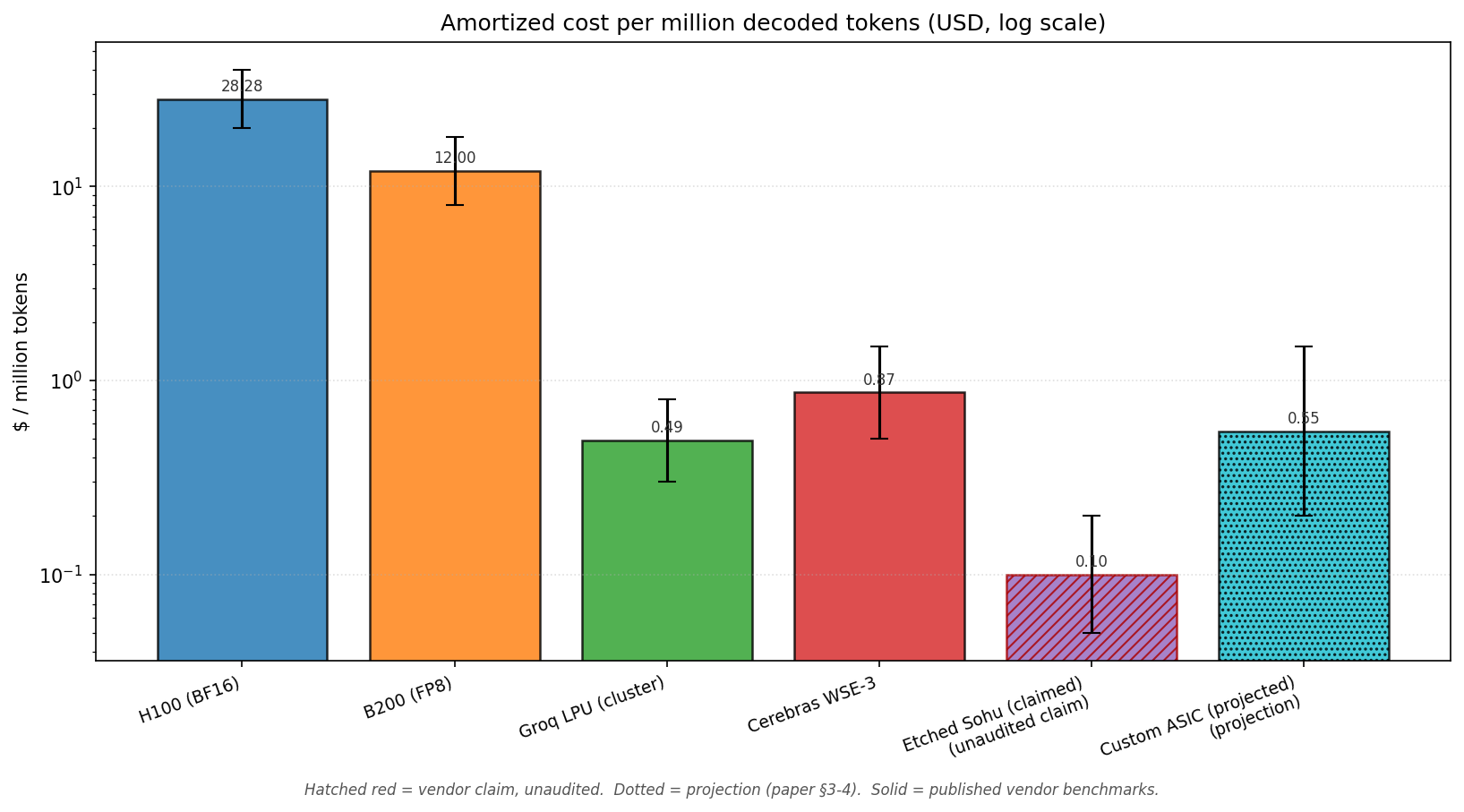
- Calibrated baselines from public Groq, Cerebras, NVIDIA MLPerf data — not vendor marketing scalars.
- Projection of Claude-class MoE inference on a 2027-feasible ASIC, with explicit sensitivity analysis.
- "Agent density" as a CEO/policymaker-facing economic metric.
- Eighteen bottlenecks, taxonomized by type and difficulty.
- Adversarial critique section anticipating ten objections.
Headline numbers (verifiable ranges)
| Decode throughput | 10-70× over H100 |
| Energy per token | 50-200× |
| Cost per million tokens | 20-100× |
| Agent density per $1M CapEx | 3,000-12,000 streams |
Each range is conditional on model size fit, batch regime, and software maturity. Single-scalar comparisons across these metrics are misleading.
Read paper (PDF) Markdown source BibTeX (.bib)
Companion papers in this series
- Paper 02 — Bottleneck-Driven Projection of Frontier-Class LLM Inference on Dedicated ASICs (above). The calibrated case study and source of the registry seed.
- Paper 03 — The Compute-Robot-Energy Triad: A Vertical-Integration Blueprint for the Musk Operating System. Strategic memo on cross-organizational integration of Tesla, SpaceX, xAI, X, Neuralink, Boring, and the new fab venture. Three meta-flywheels, five high-leverage integrations, the energy moat, the orbital-inference question (honest treatment), and a five-year capital-recapitalization sequence. [PDF] [Markdown]
- Paper 04 — The Reasoning-Tax Crisis (forthcoming). Deep dive on bottleneck B16 — why o1/o3-class reasoning models have re-based the cost economics of inference, and what serving stacks need to do about it.